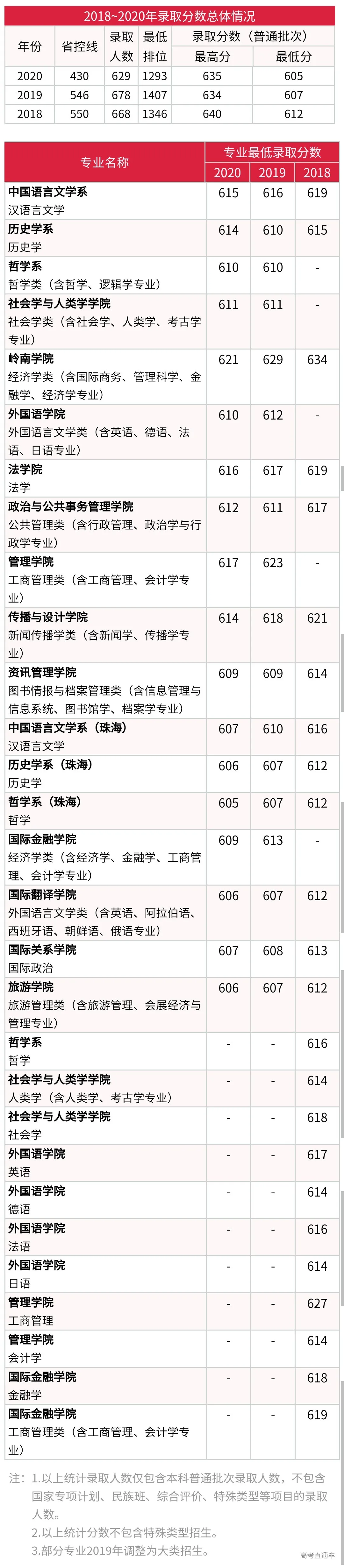
学编程太枯燥?学python缺乏动力?
那是因为你没有体验到用python为所欲为的乐趣,如果你也试试,那一定会欲罢不能。
今天Python小贤哥就教大家,如何利用python基础知识点,用爬虫每日爬取万张美女图片,至于用来做什么,我只能说:用来学习Python编程。
1、熟悉 Requests 库,Beautiful Soup 库
2、熟悉多线程爬取
(文章尾部附赠完整源码)
首先了解所需要爬取的网站,可以选择网站中的某一个内页查看,比如这个页面,从这个链接点进去
从 http://meizitu.com/a/more_1.html 这个链接进去,界面如图一所示
图一:
这是一组一组的图片,而且无论从哪张图片都可以点进详情页面。如图二所示:
所以,在这个网站中,详情图一般都会是以依次排开的方式展示,有可能几张,也有可能会更多。
这是第一步,搞清楚需要爬取网站的结构。
1、构造 url 链接,去请求图一所示的套图列表界面,拿到每一个页面中的套图列表。
2、分别进入每个套图中去,下载相应的图片。
下面给大家展示一部分不同功能的实现代码。
1. 下载界面的函数,利用 Requests 很方便实现。
2. 获取图一所示的所有套图列表,函数中 link 表示套图的链接,text表示套图的名字
3. 传入上一步中获取到的套图链接及套图名字,获取每组套图里面的图片,并保存,我在代码中注释了。
代码完成后,爬虫的爬取成果
如果把完整的代码全部运行一次,它所爬取的文件就会越来越多,如果全部爬完可能需要不少时间,所以可以在最后的代码里设置爬取的范围即可。
看完这个爬虫入门的案例后,是不是也想自己动手试试呢?如果需要的话,可以转发文章后、私信我:抓取美女,即可免费获取完整代码。
版权声明:我们致力于保护作者版权,注重分享,被刊用文章【爬虫案例(Python爬虫入门项目案例)】因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理!;

工作时间:8:00-18:00
客服电话
电子邮件
beimuxi@protonmail.com
扫码二维码
获取最新动态