欢迎大家关注公众号【哈希大数据】
我们采集信息时采集速度太大,请求速度过高,占用了大量对方服务器的资源,所以很多网站会采取一些防爬虫技术,如果你一直用一个IP爬取这个网站,很可能导致该IP被禁止访问该网站,所以为了稳定高效的完成爬虫任务,我们需要把IP问题解决了,方法就是使用代理IP,如果商用或者不差钱可以直接购买高匿代理IP。如果现在你处在爬虫探索阶段,那么可以借鉴本篇文章获取免费高匿代理IP,建成自己的代理IP池。
获取代理IP简单来说可按以下三个步骤走:第一,获取代理IP;第二,检测代理IP;第三,保存代理IP。下面进行详细介绍。
首先我们需要查看哪些网站可以提供高匿代理IP,这里给大家提供几个网站:
讯代理
快代理
西刺代理
代理66
这里给大家分享如何爬取西刺代理和讯代理的高匿IP,在浏览器中打开链接:http://www.xicidaili.com/nn/1,点击F12快捷键打开开发者工具,如下图所示。

我们只需要获取IP地址和端口,网页结构比较简单,本次代码用到了pyquery库解析HTML,pyquery之前我们没有介绍过,后面会拿出一篇具体讲解。
获取讯代理的IP,我们可以直接请求到一个json文件,如下图所示:

获取到json文件后我们直接利用json.load函数进行解析。部分代码如下图所示:

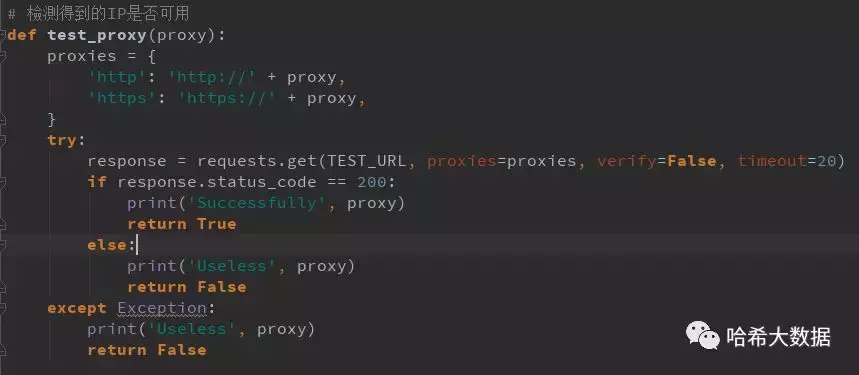
在获取到代理IP后,首先需要检测代理IP是否可用,确定可用后再保存起来,检测代理IP所用网址最好用你需要抓取信息的网址。
部分代码如下图所示:

第三步,保存获取到的代理IP
在成功检测代理IP后,本次分享将其保存到一个TXT文件中,这样处理并不是非常好,最好是将代理IP保存到数据库中在使用时能够实时检测代理IP是否可用。利用该程序保存的代理IP,在后面使用时还要先检测一下才行。
想要查看完整代码请关注公众号并回复:ip
需要注意的是代码中用到了pyquery库需要先安装好,可以直接在命令窗口中输入:pip install pyquery进行安装。
本次分享主要介绍了如何获取、检测、保存代理IP,因为很多网站会采取一些防爬虫技术,如果你一直用一个IP爬取这个网站,很可能导致该IP被禁止访问该网站,所以为了稳定高效的完成爬虫任务,我们需要很好解决代理IP问题。
版权声明:我们致力于保护作者版权,注重分享,被刊用文章【代理网址(小白学爬虫连载)】因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理!;

工作时间:8:00-18:00
客服电话
电子邮件
beimuxi@protonmail.com
扫码二维码
获取最新动态








